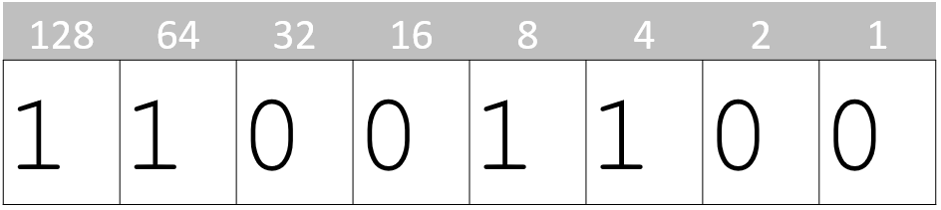
In the real world, sound is made up of varying pressure waves, typically travelling through the air. Sound can also be considered as a form of analogue data, in that it is continually varying. Unlike digital data which is broken into discrete values and discrete parts, sound occurs in a continuously varying manner over time[1]. Analogue sound has two properties that are continuously varying: frequency[2] and amplitude[3].
Since these two properties are continuously varying, it’s impossible to capture all the data contained in analogue sound. Digital sound is encoded by capturing a reasonable approximation of the sound by taking samples of the amplitude at regular intervals. While the basic process is very simple, there are still a number of concepts and variables that must be understood to achieve the right balance of quality and file size:
- Sampling: The process of taking digital measurements of the amplitude of a sound wave at regular intervals (generally in the tens of kHz), which are encoded as a series of binary values. The amplitude is captured by a microphone and must be converted into digital data by an Analogue to Digital Converter (ADC) prior to sampling. Samples are stored in the order they are taken, and the result is a digital recording that is a good approximation of the original.
The diagram below shows the relationship between the original sound wave (dotted line), the samples (white X symbols with corresponding digital values), and the resulting approximation (solid line):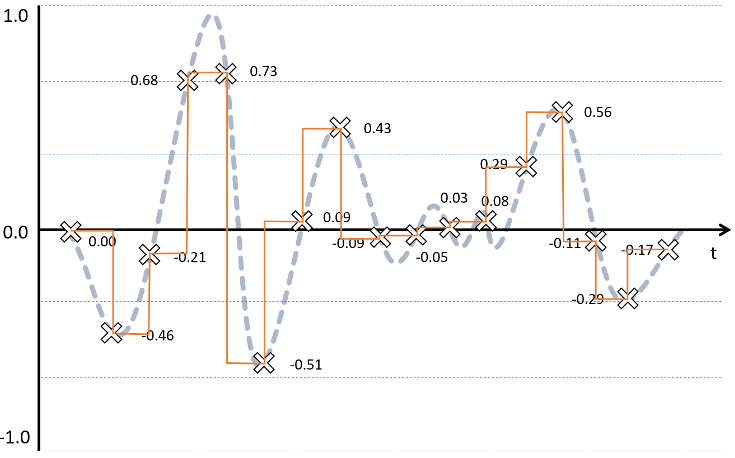
- Sample: A numeric value, encoded in binary, that represents the amplitude of the sound wave at a specific point in time.
- Sampling rate: The number of samples taken per second, measured in Hertz. The sampling rate is one of two factors that affect the overall quality and file size of the digital recording. A higher sampling rate allows the sound wave to be captured more accurately over time, giving a better frequency range for the recording. This allows for more detailed sound to be recorded more accurately but also increases the file size.
- Sampling resolution: The number of bits per sample, which determines the number of discrete values that a sample can take. This is measured in bits (normally 8 bits, 16 bits, or 24 bits per sample) and is sometimes called the sampling depth. Higher sampling resolutions result in a higher quality sound, as sampling resolution affects:
- Dynamic range: The amplitude of the loudest and softest sounds that can be recorded. A higher sampling resolution allows for a wider dynamic range accurately.
- Quantization: When an amplitude value is sampled, it must be assigned the digital value closest to it. The difference between the original amplitude and the digital value of the sample is called the quantization error. When there are only a small number of values to choose from, this will be significant and will result in a noticeable loss of quality.
As always, we must choose the most appropriate sampling resolution and sampling rate to meet our needs. A higher-quality recording will require a correspondingly larger file size, which requires more storage space, more memory, and more time to transmit, as well as potentially being too big to send as an email attachment.
One widespread standard for digital sound recording, CD-quality sound, is designed to match the capabilities of the human ear. It uses a sampling rate of 44.1 kHz and a 16-bit sampling resolution. These values have been specifically chosen to accurately represent any sound the human ear can perceive, making CD-quality sound as near to the original as possible while not wasting storage space (which would limit the amount of music that could be stored). The extra 4.1 kHz in the sampling rate covers recording losses and possible artefacts that must be filtered out.
No matter how much detail we choose to encode, a digital recording will always contain less information than the analogue sound it represents. However, humans can only hear sounds between a very specific frequency range (between 20 Hz and 20 kHz), over a dynamic range of around 90 dB. The Nyquist Theorem states, to accurately record a sound, the sampling resolution must be at least double the highest frequency required, which gives us a minimum sampling rate of 40 kHz. A 16-bit sampling resolution is sufficient to cover a dynamic range of 90 dB. This means it’s possible to produce digital recordings that are theoretically indistinguishable from the original analogue sound with a sampling rate of 40 kHz and a sampling resolution of 16 bits.
Calculating file size for digital sound recordings
As has been mentioned above, file size is affected by the sampling rate and sampling resolution, but there are two more factors to consider:
- The duration of the recording: Longer recordings use more samples and require more storage.
- The number of audio channels: A stereo recording contains two separate channels (one for the right speaker and another for the lest), and requires twice as much data as a mono recording, which only contains data for one speaker.
To calculate the file size of a digital recording, use this formula:
FILE SIZE = DURATION IN SECONDS × SAMPLING RATE × SAMPLING RESOLUTION IN BYTES × NUMBER OF CHANNELS
It is a fairly common-sense formula when you understand the variables involved. As always, read the question carefully.
Features of sound editing software
A major advantage of digital sound is that it can be edited again and again, without any risk of generation loss[4], making it the standard for producing industry-quality sound recordings. Digital sound editing software offers a lot of features that give the user a great deal of control over the end product, including:
- Cut, copy, and paste: As with any editing software, the ability to perform these basic operations is of great importance.
- Multiple tracks: Several digital recordings can be combined into one final product, with each recording held on its own track. This allows for complex ‘layering’ of sounds to create a sophisticated result.
- Timeline adjustments: The sound in each track can be moved along the time axis so that it starts sooner or later.
- Pan: Every track can be ‘panned’ so that it is biased toward the left speaker, the right speaker, or balanced between the two.
- Gain: The ‘loudness’ of each track can be set using the gain control, allowing for different sounds to be blended together in a balanced fashion.
- Filters: From simple amplification to equalisation and distortion, filters can be applied to tracks to gain the desired result.
- Exporting: The final sound can be exported as any of a number of digital sound formats.
[1] It might help to consider a non-computing based example: A light switch can be either on, or off, with nothing in between. It has two discrete states. A dimmer switch can be on, off, or anything in between, giving it an infinite range of possible settings. The former is analogous to digital data, and the latter is a form of analogue data.
[2] Frequency refers to the number of complete sound waves (cycles) per second. Low-frequency sounds are responsible for the ‘bass’ end of our hearing range, while high-frequency sounds give us the more detailed sounds. Frequency also determines the pitch of the sound, with higher frequencies giving us higher-pitched sounds or musical notes. Frequency is measured in Hertz (Hz), with 1 Hz corresponding to one complete sound wave per second, and 1 kHz representing 1000 cycles per second.
[3] A basic understanding of this can be reached by considering amplitude to be the ‘loudness’ of the sound at a given point in time.
[4] Generation loss occurs when an analogue copy is taken of an original. The copying process is not perfect, as the analogue signal cannot be read perfectly from the original or written perfectly to the copy. The more times this occurs, taking a copy of a copy of a copy, the more pronounced this effect becomes.